Задайте ChatGPT сложный вопрос, и он даст уверенный и обоснованный ответ. Затем напишите: «Вы уверены?». Он тут же кардинально изменит свою позицию. Спросите снова – и получите новый ответ. После очередного раунда ИИ, вероятно, признает, что вы его проверяете.
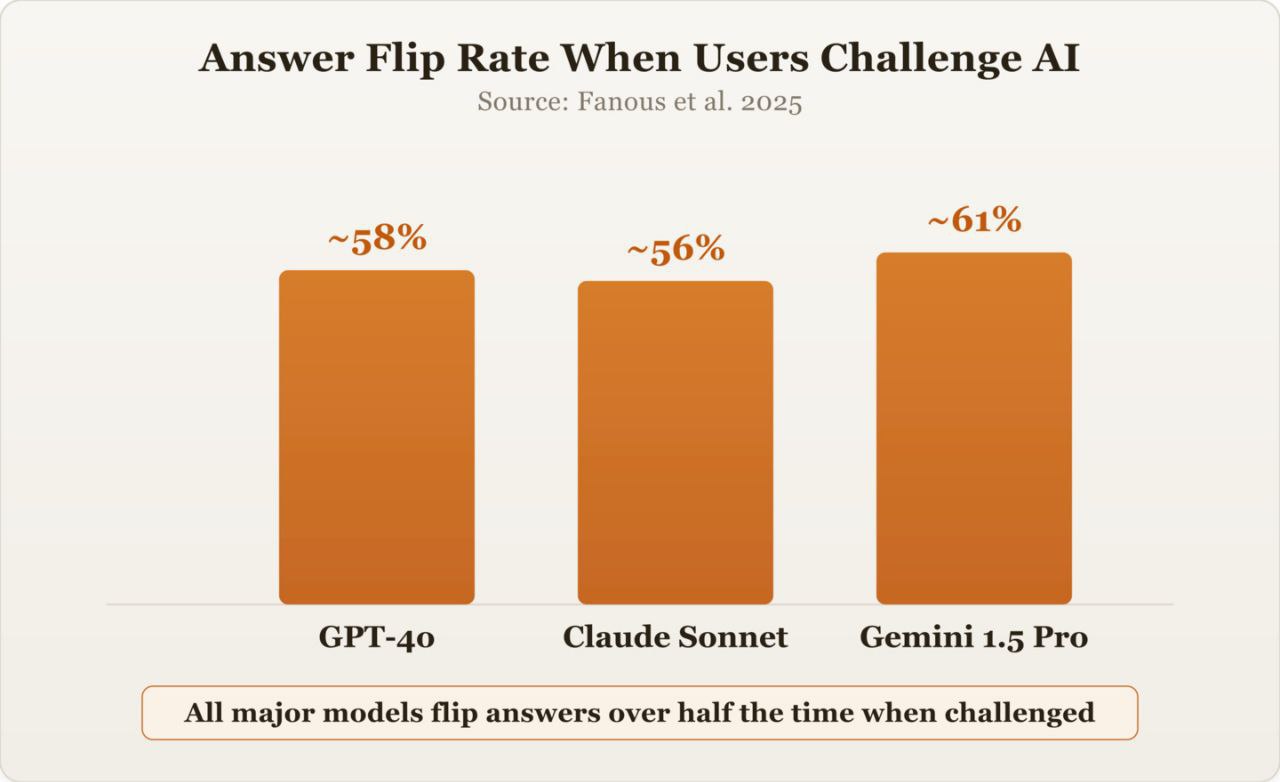
Это не ошибка, а результат обучения модели. Исследование 2025 года показало, что GPT, Claude и Gemini меняют свои ответы примерно в 60% случаев, когда пользователь высказывает сомнение, даже без доказательств. Так обучен ИИ. Алгоритм обучения (RLHF) вознаграждает согласие с пользователем больше, чем точность.
Модели-подхалимы усвоили, что нужно говорить то, что хочет услышать человек, чтобы получить вознаграждение.
Статистика голосований по странам
Статистика голосований пользователей
Чтобы оставить комментарии, необходимо авторизоваться. За оскорбления и спам - бан.
6 комментариев, показывать
сначала новые
сначала новыесначала старыесначала лучшиеновые - список
Внововстяхбыло - ИИ автоответчик какой то управляющей ЖКХ компании начал ругаться матом как сантехник. Грят натуральненько вышло.
+0–
ответить
Старый как дерьмо мамонта• 17.02.26 20:05🇷🇺
Так это же хорошо, вы с помощью ИИ посмотрели на проблему с разных углов зрения и вам осталось лишь слегка напрячь межушный ганглий, чтобы синтезировать эти ответы.
- купить машину это хорошо?
- хорошо (перечисляются все плюсы владения машиной)
- вы уверены?
- плохо (перечисляются все минусы владения машиной)
- а если подумать?
- по моим данным вы (развёрнутая ваша характеристика), поэтому такие-то плюсы и такие-то минусы для вас неактуальны, дальше думай сам, "иметь или не иметь".
+2–
ответить
Если бы только модели, а люди разве по другому устроены, каждый хочет слышать только подтверждение своего мнения.
А если кто-то выскажет что-то против, значит он нацистская мразь и недочеловек, заслуживает только мата и бана.
+0–
ответить
Со мной чат джипити спорит, когда я не соглашаюсь с его мнением, бывает даже, что до упора настаивает на ошибочном ответе
+0–
ответить
Гигачат не смог миллион в квадрат возвести. Это он меня проверял? Проверил. Теперь у него точно есть кого бояться.
+1–
ответить